Evaluating AI Agent Harnesses
An in-progress framework for thinking about and comparing agent harnesses.
An AI agent harness is all the extra information and capabilities provided to large language models (LLM) to augment the LLM's ability to complete a task. For example, the harness for a coding agent would include all the tool functions, like the bash and grep commands to search through the code base, memory and context files such as CLAUDE.md, and likewise infrastructure to improve the agent's coding ability (think Claude Code, Cursor, Codex, etc...).
Fundamentally, an LLM is a data-driven, stochastic next-token predictor. Given the context , the LLM samples the the output probability distribution to obtain the next token .
It has been emphirically shown that equipping the LLM with additional context and functions helps the LLM produce higher quality and more context-aware answers. One way to understand the positive effect of the harness is through the lens of conditioning:
(Remember that MCPs, skills, and related harness components are just user-input dependent additional tokens)
From information theory, we know that conditioning decreases entropy, which implies greater probability concentration. Keeping the coding agents example, the implication is that when you include additional context like code files or agent skills, the LLM output distribution is ideally getting more and more concentrated towards producing high-quality code.
The implementation of the harness directly affects how the LLM output probabilities are concentrated, which is related to the quality of the output. To evaluate the performance of harnesses, we can assign the quality as a real n-dimensional vector, the quality is a functional (a function of a distribution) of the LLM output based on the user input prompt .
In this formulation, a harness is said to be better than an alternative over a set of user inputs if the quality distribution of the first harness is more desireable than , where:
The term "desireable" is up to user definition, but is in general a functional on the quality distribution of the LLM outputs using harness . An example metric for desirable could be the mean, median, or even percentiles. For example, if we choose to evaluate the coding agent harnesses by the mean quality (e.g. boolean on whether test cases pass), then is a better coding harness than over a set of benchmark coding problems when:
The above is a simple framework to reason about how to evaluate agent harnesses. The implementation of an agent harness can greatly impact performance, as demonstrated by coding harness performance comparison by Matt Maher (and tweeted by Edwin from Cursor):
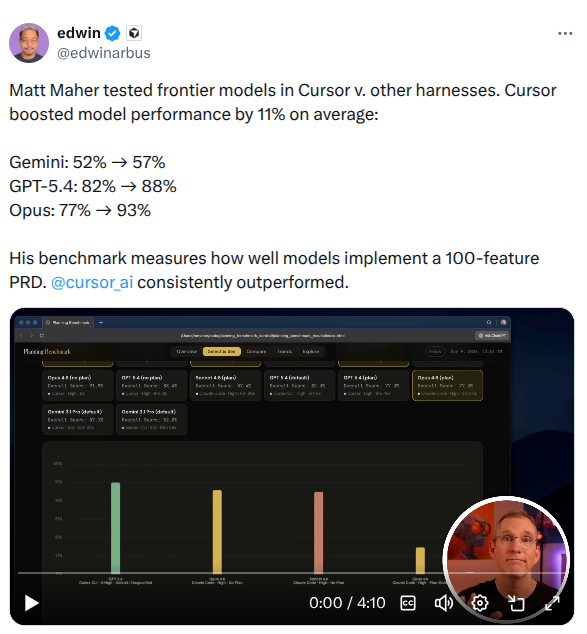
The question that remains is how can we built better agent harnesses? At a high level, we can only try to modify the base LLM (fine-tuning) or the harness implementation (e.g. system prompt, retrieval augmentation, exposing tools and MCPs, subagents, and more).
If this post interests you, please reach out!